AI
🚀 Introducing Observability Architect GPT — Your Copilot for All Things Telemetry
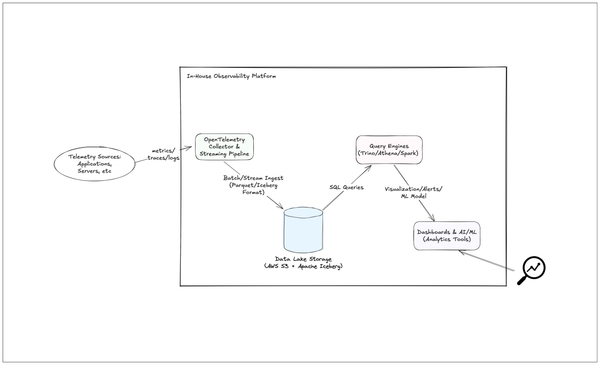
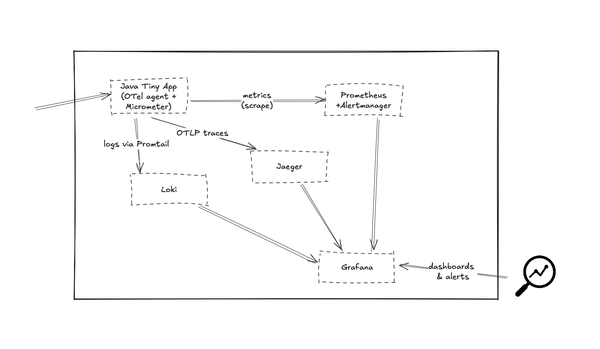
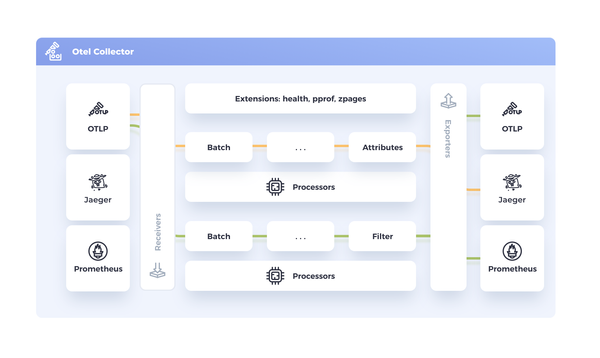
I’ve been tinkering with AI‑assisted workflows for months, and today I’m thrilled to announce Observability Architect GPT, now live in ChatGPT. Think of it as a drop‑in teammate that speaks fluent metrics, logs, and traces — and never sleeps. ChatGPT - Observability ArchitectAn expert in observability, monitoring,