Thought Leadership
Building an In-House Observability Platform with a Data Lake (AWS S3 + Apache Iceberg)
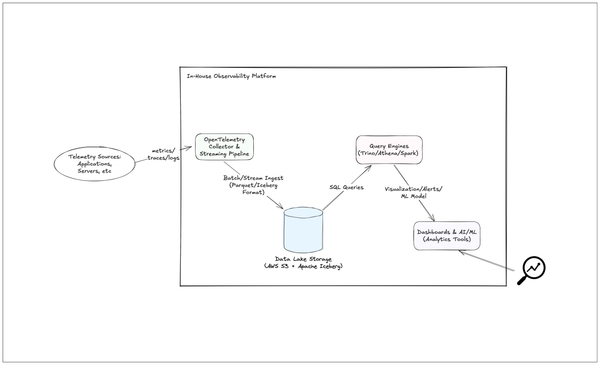
In-house observability with data lake: unify metrics, logs & traces on AWS S3 + Iceberg to slash cost, dodge vendor lock-in & boost analytics.

Thought Leadership
In-house observability with data lake: unify metrics, logs & traces on AWS S3 + Iceberg to slash cost, dodge vendor lock-in & boost analytics.

Thought Leadership
In Part 3, we explored building scalable telemetry pipelines with agents, batching, Kafka buffering, and backpressure control for resilient observability. Now let's bring it home with this last part of our blog series by addressing how to make the entire pipeline horizontally scalable and highly available, explore cost

Thought Leadership
In Part 2, we saw that scaling observability pipelines involves specialized strategies for each telemetry signal type. For metrics, scalable architectures use distributed storage, aggregation, downsampling, etc. to handle high volumes. Traces pipelines employ sampling strategies like head-based, tail-based, and remote sampling to manage trace volume. While for Logs, it

Thought Leadership
In the Part 1, we saw that a scalable pipeline architecture consists of data collection, processing, storage, and querying stages, with key design principles including horizontal scaling, stateless processing, and backpressure management. Now, let's examine specialized scaling strategies for each telemetry signal type. Scaling Observability: Designing a High-Volume

Thought Leadership
Building observability in large-scale, cloud-native systems requires collecting telemetry data (metrics, traces, and logs) at extremely high volumes. Modern platforms like Kubernetes can generate millions of metrics, traces, and log events per second, and enterprises often must handle this flood of telemetry across hybrid environments (on-premises and cloud). Designing a